Publications
Publications by categories in reversed chronological order. For a more complete record of publications, please refer to Google Scholar .
2025
- SupercomputingAddressing Reproducibility Challenges in HPC with Continuous IntegrationValérie Hayot-Sasson, Nathaniel Hudson, André Bauer, Maxime Gonthier, Ian Foster, and Kyle ChardIn Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2025
@inproceedings{hayot2025addressing, title = {Addressing Reproducibility Challenges in HPC with Continuous Integration}, author = {Hayot-Sasson, Val{\'e}rie and Hudson, Nathaniel and Bauer, Andr{\'e} and Gonthier, Maxime and Foster, Ian and Chard, Kyle}, booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis}, pages = {437--457}, year = {2025}, } - PNASCartesian equivariant representations for learning and understanding molecular orbitalsDaniel S. King, Daniel Grzenda, Ray Zhu, Nathaniel Hudson, Ian Foster, Bingqing Cheng, and Laura GagliardiProceedings of the National Academy of Sciences, 2025
Orbital properties such as energies and bonding character are vital to how chemists understand fundamental chemical phenomena such as bonding, Lewis structures, electronegativity, and excited states. Yet, relatively little effort has gone into developing deep learning representations of molecular orbitals. This research presents a deep learning model, the Cartesian Equivariant Orbital Network (CEONET), that improves how molecular orbitals are represented and analyzed in machine learning frameworks. By working with the symmetries inherent to molecular orbital coefficients, CEONET accurately predicts key orbital properties, addressing a significant gap in the application of machine learning to electronic structure theory and enabling the automated application and interpretation of advanced electronic structure calculations. Qualitative and quantitative orbital properties such as bonding/antibonding character, localization, and orbital energies are critical to how chemists understand reactivity, catalysis, and excited-state behavior. Despite this, representations of orbitals in deep learning models have been very underdeveloped relative to representations of molecular geometries and Hamiltonians. Here, we apply state-of-the-art equivariant deep learning architectures to the task of assigning global labels to orbitals, namely energies characterizations, given the molecular coefficients from Hartree–Fock or density functional theory. The architecture we have developed, the Cartesian Equivariant Orbital Network (CEONET), shows how molecular orbital coefficients are readily featurized as equivariant node features common to all graph-based machine-learned potentials. We find that CEONET performs well at predicting difficult quantitative labels such as the orbital energy and orbital entropy. Furthermore, we find that the CEONET representation provides an intuitive latent space for differentiating orbital character for the qualitative assignment of e.g. bonding or antibonding character. In addition to providing a useful representation for further integrating deep learning with electronic structure theory, we expect CEONET to be useful for automatizing and interpreting the results of advanced electronic structure methods such as complete active space self-consistent field theory. In particular, the ability of CEONET to infer multireference character via the orbital entropy paves the way toward the machine-learned selection of active spaces.
@article{doi:10.1073/pnas.2510235122, author = {King, Daniel S. and Grzenda, Daniel and Zhu, Ray and Hudson, Nathaniel and Foster, Ian and Cheng, Bingqing and Gagliardi, Laura}, title = {Cartesian equivariant representations for learning and understanding molecular orbitals}, journal = {Proceedings of the National Academy of Sciences}, volume = {122}, number = {48}, pages = {e2510235122}, year = {2025}, doi = {10.1073/pnas.2510235122}, url = {https://www.pnas.org/doi/abs/10.1073/pnas.2510235122}, eprint = {https://www.pnas.org/doi/pdf/10.1073/pnas.2510235122}, } - eScienceSteering an Active Learning Workflow Towards Novel Materials Discovery via Queue PrioritizationMarcus Schwarting, Logan Ward, Nathaniel Hudson, Xiaoli Yan, Ben Blaiszik, Eliu Huerta, and Ian FosterIn 2025 IEEE International Conference on e-Science, 2025
This paper received the “Best Paper” award for the conference.
Generative AI poses both opportunities and risks for solving inverse design problems in the sciences. Generative tools provide the ability to expand and refine a search space autonomously, but do so at the cost of exploring low-quality regions until sufficiently fine tuned. Here, we propose a queue prioritization algorithm that combines generative modeling and active learning in the context of a distributed workflow for exploring complex design spaces. We find that incorporating an active learning model to prioritize top design candidates can prevent a generative AI workflow from expending resources on nonsensical candidates and halt potential generative model decay. For an existing generative AI workflow for discovering novel molecular structure candidates for carbon capture, our active learning approach significantly increases the number of high-quality candidates identified by the generative model. We find that, out of 1000 novel candidates, our workflow without active learning can generate an average of 281 high-performing candidates, while our proposed prioritization with active learning can generate an average 604 high-performing candidates.
@inproceedings{schwarting2025steering, title = {Steering an Active Learning Workflow Towards Novel Materials Discovery via Queue Prioritization}, author = {Schwarting, Marcus and Ward, Logan and Hudson, Nathaniel and Yan, Xiaoli and Blaiszik, Ben and Huerta, Eliu and Foster, Ian}, year = {2025}, booktitle = {2025 IEEE International Conference on e-Science}, publisher = {Institute of Electrical and Electronics Engineers}, } - fgcs
 Flight: A FaaS-Based Framework for Complex and Hierarchical Federated LearningNathaniel Hudson, Valerie Hayot-Sasson, Yadu Babuji, Matt Baughman, J Gregory Pauloski, Ryan Chard, Ian Foster, and Kyle ChardFuture Generation Computer Systems, 2025
Flight: A FaaS-Based Framework for Complex and Hierarchical Federated LearningNathaniel Hudson, Valerie Hayot-Sasson, Yadu Babuji, Matt Baughman, J Gregory Pauloski, Ryan Chard, Ian Foster, and Kyle ChardFuture Generation Computer Systems, 2025Federated Learning (FL) is a decentralized machine learning paradigm where models are trained on distributed devices and are aggregated at a central server. Existing FL frameworks assume simple two-tier network topologies where end devices are directly connected to the aggregation server. While this is a practical mental model, it does not exploit the inherent topology of real-world distributed systems like the Internet-of-Things. We present Flight, a novel FL framework that supports complex hierarchical multi-tier topologies, asynchronous aggregation, and decouples the control plane from the data plane. We compare the performance of Flight against Flower, a state-of-the-art FL framework. Our results show that Flight scales beyond Flower, supporting up to 2048 simultaneous devices, and reduces FL makespan across several models. Finally, we show that Flight’s hierarchical FL model can reduce communication overheads by more than 60%.
@article{hudson2025flight, abbr = fgcs, title = {Flight: A {FaaS}-Based Framework for Complex and Hierarchical Federated Learning}, author = {Hudson, Nathaniel and Hayot-Sasson, Valerie and Babuji, Yadu and Baughman, Matt and Pauloski, J Gregory and Chard, Ryan and Foster, Ian and Chard, Kyle}, journal = {Future Generation Computer Systems}, year = {2025}, show_abstract = {true}, } - PreprintAERO: An autonomous platform for continuous researchValérie Hayot-Sasson, Abby Stevens, Nicholson Collier, Sudershan Sridhar, Kyle Conroy, J. Gregory Pauloski, Yadu Babuji, Maxime Gonthier, Nathaniel Hudson, Dante D. Sanchez-Gallegos, Ian Foster, Jonathan Ozik, and Kyle ChardarXiv preprint arxiv:2505.18408, 2025
@article{hayotsasson2025aero, title = {{AERO}: An autonomous platform for continuous research}, author = {Hayot-Sasson, Val\'{e}rie and Stevens, Abby and Collier, Nicholson and Sridhar, Sudershan and Conroy, Kyle and Pauloski, J. Gregory and Babuji, Yadu and Gonthier, Maxime and Hudson, Nathaniel and Sanchez-Gallegos, Dante D. and Foster, Ian and Ozik, Jonathan and Chard, Kyle}, journal = {arXiv preprint arxiv:2505.18408}, year = {2025} } - PreprintTopology-Aware Knowledge Propagation in Decentralized LearningMansi Sakarvadia, Nathaniel Hudson, Tian Li, Ian Foster, and Kyle ChardarXiv preprint arXiv:2505.11760, 2025
@article{sakarvadia2025topology, title = {Topology-Aware Knowledge Propagation in Decentralized Learning}, author = {Sakarvadia, Mansi and Hudson, Nathaniel and Li, Tian and Foster, Ian and Chard, Kyle}, journal = {arXiv preprint arXiv:2505.11760}, year = {2025}, } - PreprintMOFA: Discovering Materials for Carbon Capture with a GenAI- and Simulation-Based WorkflowXiaoli Yan, Nathaniel Hudson, Hyun Park, Daniel Grzenda, J. Gregory Pauloski, Marcus Schwarting, Haochen Pan, Hassan Harb, Samuel Foreman, Chris Knight, Tom Gibbs, Kyle Chard, Santanu Chaudhuri, Emad Tajkhorshid, Ian Foster, Mohamad Moosavi, Logan Ward, and E. A. Huerta2025
@misc{yan2025mofadiscoveringmaterialscarbon, title = {{MOFA}: Discovering Materials for Carbon Capture with a GenAI- and Simulation-Based Workflow}, author = {Yan, Xiaoli and Hudson, Nathaniel and Park, Hyun and Grzenda, Daniel and Pauloski, J. Gregory and Schwarting, Marcus and Pan, Haochen and Harb, Hassan and Foreman, Samuel and Knight, Chris and Gibbs, Tom and Chard, Kyle and Chaudhuri, Santanu and Tajkhorshid, Emad and Foster, Ian and Moosavi, Mohamad and Ward, Logan and Huerta, E. A.}, year = {2025}, eprint = {2501.10651}, archiveprefix = {arXiv}, primaryclass = {cs.DC}, url = {https://arxiv.org/abs/2501.10651}, } - ICLR ’25Mitigating Memorization In Language ModelsMansi Sakarvadia, Aswathy Ajith, Arham Khan, Nathaniel Hudson, Caleb Geniesse, Kyle Chard, Yaoqing Yang, Ian Foster, and Michael W MahoneyIn to appear in the proceedings of The Thirteenth International Conference on Learning Representations, 2025
This paper received a “Spotlight” distinction for the 2025 ICLR conference.
@inproceedings{sakarvadia2025mitigating, title = {Mitigating Memorization In Language Models}, author = {Sakarvadia, Mansi and Ajith, Aswathy and Khan, Arham and Hudson, Nathaniel and Geniesse, Caleb and Chard, Kyle and Yang, Yaoqing and Foster, Ian and Mahoney, Michael W}, booktitle = {to appear in the proceedings of The Thirteenth International Conference on Learning Representations}, year = {2025}, } - TMLRCausal Discovery over High-Dimensional Structured Hypothesis Spaces with Causal Graph PartitioningAshka Shah, Adela DePavia, Nathaniel Hudson, Ian Foster, and Rick StevensTransactions on Machine Learning Research (TMLR), 2025
The aim in many sciences is to understand the mechanisms that underlie the observed distribution of variables, starting from a set of initial hypotheses. Causal discovery allows us to infer mechanisms as sets of cause and effect relationships in a generalized way – without necessarily tailoring to a specific domain. Causal discovery algorithms search over a structured hypothesis space, defined by the set of directed acyclic graphs, to find the graph that best explains the data. For high-dimensional problems, however, this search becomes intractable and scalable algorithms for causal discovery are needed to bridge the gap. In this paper, we define a novel causal graph partition that allows for divide-and-conquer causal discovery with theoretical guarantees. We leverage the idea of a superstructure – a set of learned or existing candidate hypotheses – to partition the search space. We prove under certain assumptions that learning with a causal graph partition always yields the Markov Equivalence Class of the true causal graph. We show our algorithm achieves comparable accuracy and a faster time to solution for biologically-tuned synthetic networks and networks up to 10^4 variables. This makes our method applicable to gene regulatory network inference and other domains with high-dimensional structured hypothesis spaces.
@article{shah2025causal, title = {Causal Discovery over High-Dimensional Structured Hypothesis Spaces with Causal Graph Partitioning}, author = {Shah, Ashka and DePavia, Adela and Hudson, Nathaniel and Foster, Ian and Stevens, Rick}, journal = {Transactions on Machine Learning Research (TMLR)}, year = {2025}, }
2024
- PreprintSoK: On Finding Common Ground in Loss Landscapes Using Deep Model Merging TechniquesArham Khan, Todd Nief, Nathaniel Hudson, Mansi Sakarvadia, Daniel Grzenda, Aswathy Ajith, Jordan Pettyjohn, Kyle Chard, and Ian FosterarXiv preprint arXiv:2410.12927, 2024
@article{khan2024sok, title = {{SoK}: On Finding Common Ground in Loss Landscapes Using Deep Model Merging Techniques}, author = {Khan, Arham and Nief, Todd and Hudson, Nathaniel and Sakarvadia, Mansi and Grzenda, Daniel and Ajith, Aswathy and Pettyjohn, Jordan and Chard, Kyle and Foster, Ian}, journal = {arXiv preprint arXiv:2410.12927}, year = {2024} } - eScienceTaPS: A Performance Evaluation Suite for Task-based Execution FrameworksJ. Gregory Pauloski, Valerie Hayot-Sasson, Maxime Gonthier, Nathaniel Hudson, Haochen Pan, Sicheng Zhou, Ian Foster, and Kyle ChardIn 2024 IEEE International Conference on e-Science, 2024
Task-based execution frameworks, such as in parallel programming libraries, computational workflow systems, and function-as-a-service platforms, enable the composition of distinct tasks into a single, unified application designed to achieve a computational goal. Task-based execution frameworks abstract the parallel execution of an application’s tasks on arbitrary hardware. Research into these task executors has accelerated as computational sciences increasingly need to take advantage of parallel compute and/or heterogeneous hardware. However, the lack of evaluation standards makes it challenging to compare and contrast novel systems against existing implementations. Here, we introduce TaPS, the Task Performance Suite, to support continued research in parallel task executor frameworks. TaPS provides (1) a unified, modular interface for writing and evaluating applications using arbitrary execution frameworks and data management systems and (2) an initial set of synthetic and real-world science applications available within TaPS. We discuss how the design of TaPS supports the reliable evaluation of frameworks and demonstrate TaPS through a survey of benchmarks using the provided reference applications.
@inproceedings{pauloski2024taps, title = {{TaPS}: A Performance Evaluation Suite for Task-based Execution Frameworks}, author = {Pauloski, J. Gregory and Hayot-Sasson, Valerie and Gonthier, Maxime and Hudson, Nathaniel and Pan, Haochen and Zhou, Sicheng and Foster, Ian and Chard, Kyle}, year = {2024}, booktitle = {2024 IEEE International Conference on e-Science}, publisher = {Institute of Electrical and Electronics Engineers}, } - eScienceAn Empirical Investigation of Container Building Strategies and Warm Times to Reduce Cold Starts in Scientific Computing Serverless FunctionsAndré Bauer, Maxime Gonthier, Haochen Pan, Ryan Chard, Daniel Grzenda, Martin Straesser, J. Gregory Pauloski, Alok Kamatar, Matt Baughman, Nathaniel Hudson, Ian Foster, and Kyle ChardIn 2024 IEEE International Conference on e-Science, 2024
Serverless computing has revolutionized application development and deployment by abstracting infrastructure management, allowing developers to focus on writing code. To do so, serverless platforms dynamically create execution environments, often using containers. The cost to create and deploy these environments is known as “cold start” latency, and this cost can be particularly detrimental to scientific computing workloads characterized by sporadic and dynamic demands. We investigate methods to mitigate cold start issues in scientific computing applications by pre-installing Python packages in container images. Using data from Globus Compute and Binder, we empirically analyze cold start behavior and evaluate four strategies for building containers, including fully pre-built environments and dynamic, on-demand installations. Our results show that pre-installing all packages reduces initial cold start time but requires significant storage. Conversely, dynamic installation offers lower storage requirements but incurs repetitive delays. Additionally, we implemented a simulator and assessed the impact of different warm times, finding that moderate warm times significantly reduce cold starts without the excessive overhead of maintaining always-hot states.
@inproceedings{bauer2024empirical, title = {An Empirical Investigation of Container Building Strategies and Warm Times to Reduce Cold Starts in Scientific Computing Serverless Functions}, author = {Bauer, Andr\'{e} and Gonthier, Maxime and Pan, Haochen and Chard, Ryan and Grzenda, Daniel and Straesser, Martin and Pauloski, J. Gregory and Kamatar, Alok and Baughman, Matt and Hudson, Nathaniel and Foster, Ian and Chard, Kyle}, year = {2024}, booktitle = {2024 IEEE International Conference on e-Science}, publisher = {Institute of Electrical and Electronics Engineers}, } - JDIQThinking in Categories: A Survey on Assessing the Quality for Time Series SynthesisMichael Stenger, André Bauer, Thomas Prantl, Robert Leppich, Nathaniel Hudson, Kyle Chard, Ian Foster, and Samuel KounevJournal of Data and Information Quality, May 2024Just Accepted
Time series data are widely used and provide a wealth of information for countless applications. However, some applications are faced with a limited amount of data, or the data cannot be used due to confidentiality concerns. To overcome these obstacles, time series can be generated synthetically. For example, electrocardiograms can be synthesized to make them available for building models to predict conditions such as cardiac arrhythmia without leaking patient information. Although many different approaches to time series synthesis have been proposed, evaluating the quality of synthetic time series data poses unique challenges and remains an open problem, as there is a lack of a clear definition of what constitutes a “good” synthesis. To this end, we present a comprehensive literature survey to identify different aspects of synthesis quality and their relationships. Based on this, we propose a definition of synthesis quality and a systematic evaluation procedure for assessing it. With this work, we aim to provide a common language and criteria for evaluating synthetic time series data. Our goal is to promote more rigorous and reproducible research in time series synthesis by enabling researchers and practitioners to generate high-quality synthetic time series data.
@article{stenger2024thinking, author = {Stenger, Michael and Bauer, Andr\'{e} and Prantl, Thomas and Leppich, Robert and Hudson, Nathaniel and Chard, Kyle and Foster, Ian and Kounev, Samuel}, title = {Thinking in Categories: A Survey on Assessing the Quality for Time Series Synthesis}, year = {2024}, address = {New York, NY, USA}, issn = {1936-1955}, url = {https://doi.org/10.1145/3666006}, doi = {10.1145/3666006}, note = {Just Accepted}, journal = {Journal of Data and Information Quality}, month = may, keywords = {Time series, synthetic data generation, measures}, publisher = {Association for Computing Machinery}, } - PreprintDeep Learning for Molecular OrbitalsDaniel King, Daniel Grzenda, Ray Zhu, Nathaniel Hudson, Ian Foster, and Laura GagliardiMay 2024
The advancement of deep learning in chemistry has resulted in state-of-the-art models that incorporate an increasing number of concepts from standard quantum chemistry, such as orbitals and Hamiltonians. With an eye towards the future development of these deep learning approaches, we present here what we believe to be the first work focused on assigning labels to orbitals, namely energies and characterizations, given the real-space descriptions of these orbitals from standard electronic structure theories such as Hartree-Fock. In addition to providing a foundation for future development, we expect these models to have immediate impact in automatizing and interpreting the results of advanced electronic structure approaches for chemical reactivity and spectroscopy.
@article{king2024deep, title = {Deep Learning for Molecular Orbitals}, author = {King, Daniel and Grzenda, Daniel and Zhu, Ray and Hudson, Nathaniel and Foster, Ian and Gagliardi, Laura}, year = {2024}, } - Sensor LettersRuralAI in Tomato Farming: Integrated Sensor System, Distributed Computing and Hierarchical Federated Learning for Crop Health MonitoringHarish Devaraj, Shaleeza Sohail, Boyang Li, Nathaniel Hudson, Matt Baughman, Kyle Chard, Ryan Chard, Enrico Casella, Ian Foster, and Omer RanaIEEE Sensors Letters, May 2024
Precision horticulture is evolving due to scalable sensor deployment and machine learning integration. These advancements boost the operational efficiency of individual farms, balancing the benefits of analytics with autonomy requirements. However, given concerns that affect wide geographic regions (e.g., climate change), there is a need to apply models that span farms. Federated Learning (FL) has emerged as a potential solution. FL enables decentralized machine learning (ML) across different farms without sharing private data. Traditional FL assumes simple 2-tier network topologies and thus falls short of operating on more complex networks found in real-world agricultural scenarios. Networks vary across crops and farms, and encompass various sensor data modes, extending across jurisdictions. New hierarchical FL (HFL) approaches are needed for more efficient and context-sensitive model sharing, accommodating regulations across multiple jurisdictions. We present the RuralAI architecture deployment for tomato crop monitoring, featuring sensor field units for soil, crop, and weather data collection. HFL with personalization is used to offer localized and adaptive insights. Model management, aggregation, and transfers are facilitated via a flexible approach, enabling seamless communication between local devices, edge nodes, and the cloud.
@article{devaraj2024rural, author = {Devaraj, Harish and Sohail, Shaleeza and Li, Boyang and Hudson, Nathaniel and Baughman, Matt and Chard, Kyle and Chard, Ryan and Casella, Enrico and Foster, Ian and Rana, Omer}, journal = {IEEE Sensors Letters}, title = {RuralAI in Tomato Farming: Integrated Sensor System, Distributed Computing and Hierarchical Federated Learning for Crop Health Monitoring}, year = {2024}, volume = {}, number = {}, pages = {1-4}, keywords = {Sensors;Crops;Monitoring;Fuzzy logic;Cloud computing;Sensor systems;Data models;Rural areas;Horticulture;Precision agriculture;Machine learning;Farming;Distributed computing;Federated learning;Climate change;Internet of Things (IoT);sensor systems;sensor applications;federated learning;precision horticulture}, doi = {10.1109/LSENS.2024.3384935}, } - FGCSQoS-aware edge AI placement and scheduling with multiple implementations in FaaS-based edge computingNathaniel Hudson, Hana Khamfroush, Matt Baughman, Daniel E. Lucani, Kyle Chard, and Ian FosterFuture Generation Computer Systems, May 2024
Resource constraints on the computing continuum require that we make smart decisions for serving AI-based services at the network edge. AI-based services typically have multiple implementations (e.g., image classification implementations include SqueezeNet, DenseNet, and others) with varying trade-offs (e.g., latency and accuracy). The question then is how should AI-based services be placed across Function-as-a-Service (FaaS) based edge computing systems in order to maximize total Quality-of-Service (QoS). To address this question, we propose a problem that jointly aims to solve (i) edge AI service placement and (ii) request scheduling. These are done across two time-scales (one for placement and one for scheduling). We first cast the problem as an integer linear program. We then decompose the problem into separate placement and scheduling subproblems and prove that both are NP-hard. We then propose a novel placement algorithm that places services while considering device-to-device communication across edge clouds to offload requests to one another. Our results show that the proposed placement algorithm is able to outperform a state-of-the-art placement algorithm for AI-based services, and other baseline heuristics, with regard to maximizing total QoS. Additionally, we present a federated learning-based framework, FLIES, to predict the future incoming service requests and their QoS requirements. Our results also show that our FLIES algorithm is able to outperform a standard decentralized learning baseline for predicting incoming requests and show comparable predictive performance when compared to centralized training.
@article{hudson2024qos, title = {QoS-aware edge AI placement and scheduling with multiple implementations in FaaS-based edge computing}, journal = {Future Generation Computer Systems}, volume = {157}, pages = {250-263}, year = {2024}, issn = {0167-739X}, doi = {https://doi.org/10.1016/j.future.2024.03.035}, url = {https://www.sciencedirect.com/science/article/pii/S0167739X24001067}, author = {Hudson, Nathaniel and Khamfroush, Hana and Baughman, Matt and Lucani, Daniel E. and Chard, Kyle and Foster, Ian}, keywords = {Service placement, Federated learning, Serverless edge computing, Edge intelligence, Quality-of-service}, } - BDCATTrillion Parameter AI Serving Infrastructure for Scientific Discovery: A Survey and VisionNathaniel Hudson, J. Gregory Pauloski, Matt Baughman, Alok Kamatar, Mansi Sakarvadia, Logan Ward, Ryan Chard, André Bauer, Maksim Levental, Wenyi Wang, Will Engler, Owen Price Skelly, Ben Blaiszik, Rick Stevens, Kyle Chard, and Ian FosterIn Proceedings of the IEEE/ACM International Conference on Big Data Computing, Applications and Technologies, May 2024(Accepted for publication)
Deep learning methods are transforming research, enabling new techniques, and ultimately leading to new discoveries. As the demand for more capable AI models continues to grow, we are now entering an era of Trillion Parameter Models (TPM), or models with more than a trillion parameters—such as Huawei’s PanGu-Σ. We describe a vision for the ecosystem of TPM users and providers that caters to the specific needs of the scientific community. We then outline the significant technical challenges and open problems in system design for serving TPMs to enable scientific research and discovery. Specifically, we describe the requirements of a comprehensive software stack and interfaces to support the diverse and flexible requirements of researchers.
@inproceedings{hudson2024trillion, title = {Trillion Parameter AI Serving Infrastructure for Scientific Discovery: A Survey and Vision}, author = {Hudson, Nathaniel and Pauloski, J. Gregory and Baughman, Matt and Kamatar, Alok and Sakarvadia, Mansi and Ward, Logan and Chard, Ryan and Bauer, Andr\'{e} and Levental, Maksim and Wang, Wenyi and Engler, Will and Skelly, Owen Price and Blaiszik, Ben and Stevens, Rick and Chard, Kyle and Foster, Ian}, booktitle = {Proceedings of the IEEE/ACM International Conference on Big Data Computing, Applications and Technologies}, year = {2024}, publisher = {Association for Computing Machinery}, note = {(Accepted for publication)}, }
2023
- SC WorkshopTournament-Based Pretraining to Accelerate Federated LearningMatt Baughman, Nathaniel Hudson, Ryan Chard, Andre Bauer, Ian Foster, and Kyle ChardIn Proceedings of the SC ’23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis,
, , May 2023Denver ,CO ,USA ,Advances in hardware, proliferation of compute at the edge, and data creation at unprecedented scales have made federated learning (FL) necessary for the next leap forward in pervasive machine learning. For privacy and network reasons, large volumes of data remain stranded on endpoints located in geographically austere (or at least austere network-wise) locations. However, challenges exist to the effective use of these data. To solve the system and functional level challenges, we present an three novel variants of a serverless federated learning framework. We also present tournament-based pretraining, which we demonstrate significantly improves model performance in some experiments. Overall, these extensions to FL and our novel training method enable greater focus on science rather than ML development.
- IMMMeasurement and Applications: Exploring the Challenges and Opportunities of Hierarchical Federated Learning in Sensor ApplicationsMelanie Po-Leen Ooi, Shaleeza Sohail, Victoria Guiying Huang, Nathaniel Hudson, Matt Baughman, Omer Rana, Annika Hinze, Kyle Chard, Ryan Chard, Ian Foster, Theodoros Spyridopoulos, and Harshaan NagraIEEE Instrumentation & Measurement Magazine, May 2023
Sensor applications have become ubiquitous in modern society as the digital age continues to advance. AI-based techniques (e.g., machine learning) are effective at extracting actionable information from large amounts of data. An example would be an automated water irrigation system that uses AI-based techniques on soil quality data to decide how to best distribute water. However, these AI-based techniques are costly in terms of hardware resources, and Internet-of-Things (IoT) sensors are resource-constrained with respect to processing power, energy, and storage capacity. These limitations can compromise the security, performance, and reliability of sensor-driven applications. To address these concerns, cloud computing services can be used by sensor applications for data storage and processing. Unfortunately, cloud-based sensor applications that require real-time processing, such as medical applications (e.g., fall detection and stroke prediction), are vulnerable to issues such as network latency due to the sparse and unreliable networks between the sensor nodes and the cloud server [1]. As users approach the edge of the communications network, latency issues become more severe and frequent. A promising alternative is edge computing, which provides cloud-like capabilities at the edge of the network by pushing storage and processing capabilities from centralized nodes to edge devices that are closer to where the data are gathered, resulting in reduced network delays [2], [3].
@article{ooi2023measurement, journal = {IEEE Instrumentation \& Measurement Magazine}, title = {Measurement and Applications: Exploring the Challenges and Opportunities of Hierarchical Federated Learning in Sensor Applications}, author = {Ooi, Melanie Po-Leen and Sohail, Shaleeza and Huang, Victoria Guiying and Hudson, Nathaniel and Baughman, Matt and Rana, Omer and Hinze, Annika and Chard, Kyle and Chard, Ryan and Foster, Ian and Spyridopoulos, Theodoros and Nagra, Harshaan}, year = {2023}, volume = {26}, number = {9}, pages = {21-31}, doi = {10.1109/MIM.2023.10328671}, } - PreprintAttention Lens: A Tool for Mechanistically Interpreting the Attention Head Information Retrieval MechanismMansi Sakarvadia, Arham Khan, Aswathy Ajith, Daniel Grzenda, Nathaniel Hudson, André Bauer, Kyle Chard, and Ian FosterMay 2023
Transformer-based Large Language Models (LLMs) are the state-of-the-art for nat- ural language tasks. Recent work has attempted to decode, by reverse engineering the role of linear layers, the internal mechanisms by which LLMs arrive at their final predictions for text completion tasks. Yet little is known about the specific role of attention heads in producing the final token prediction. We propose Attention Lens, a tool that enables researchers to translate the outputs of attention heads into vocabulary tokens via learned attention-head-specific transformations called lenses. Preliminary findings from our trained lenses indicate that attention heads play highly specialized roles in language models. The code for Attention Lens is available at github.com/msakarvadia/AttentionLens.
@misc{sakarvadia2023attention, title = {Attention Lens: A Tool for Mechanistically Interpreting the Attention Head Information Retrieval Mechanism}, author = {Sakarvadia, Mansi and Khan, Arham and Ajith, Aswathy and Grzenda, Daniel and Hudson, Nathaniel and Bauer, André and Chard, Kyle and Foster, Ian}, year = {2023}, eprint = {2310.16270}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, } - BlackBoxNLPMemory Injections: Correcting Multi-Hop Reasoning Failures during Inference in Transformer-Based Language ModelsMansi Sakarvadia, Aswathy Ajith, Arham Khan, Daniel Grzenda, Nathaniel Hudson, André Bauer, Kyle Chard, and Ian FosterMay 2023
Answering multi-hop reasoning questions requires retrieving and synthesizing information from diverse sources. Large Language Models (LLMs) struggle to perform such reasoning consistently. Here we propose an approach to pinpoint and rectify multi-hop reasoning failures through targeted memory injections on LLM attention heads. First, we analyze the per-layer activations of GPT-2 models in response to single and multi-hop prompts. We then propose a mechanism that allows users to inject pertinent prompt-specific information, which we refer to as "memories," at critical LLM locations during inference. By thus enabling the LLM to incorporate additional relevant information during inference, we enhance the quality of multi-hop prompt completions. We show empirically that a simple, efficient, and targeted memory injection into a key attention layer can often increase the probability of the desired next token in multi-hop tasks, by up to 424%.
@misc{sakarvadia2023memory, title = {Memory Injections: Correcting Multi-Hop Reasoning Failures during Inference in Transformer-Based Language Models}, author = {Sakarvadia, Mansi and Ajith, Aswathy and Khan, Arham and Grzenda, Daniel and Hudson, Nathaniel and Bauer, André and Chard, Kyle and Foster, Ian}, year = {2023}, eprint = {2309.05605}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, } - WF-IoTAdversarial Predictions of Data Distributions Across Federated Internet-of-Things DevicesSamir Rajani, Dario Dematties, Nathaniel Hudson, Kyle Chard, Nicola Ferrier, Rajesh Sankaran, and Peter BeckmanIn 2023 IEEE World Forum on Internet of Things (WF-IoT), Oct 2023
Federated learning (FL) is increasingly becoming the default approach for training machine learning models across decentralized Internet-of-Things (IoT) devices. A key advantage of FL is that no raw data are communicated across the network, providing an immediate layer of privacy. Despite this, recent works have demonstrated that data reconstruction can be done with the locally trained model updates which are communicated across the network. However, many of these works have limitations with regard to how the gradients are computed in backpropagation. In this work, we demonstrate that the model weights shared in FL can expose revealing information about the local data distributions of IoT devices. This leakage could expose sensitive information to malicious actors in a distributed system. We further discuss results which show that injecting noise into model weights is ineffective at preventing data leakage without seriously harming the global model accuracy.
@inproceedings{rajani2023adversarial, title = {Adversarial Predictions of Data Distributions Across Federated Internet-of-Things Devices}, author = {Rajani, Samir and Dematties, Dario and Hudson, Nathaniel and Chard, Kyle and Ferrier, Nicola and Sankaran, Rajesh and Beckman, Peter}, booktitle = {2023 IEEE World Forum on Internet of Things (WF-IoT)}, publisher = {Institute of Electrical and Electronics Engineers}, month = oct, year = {2023}, } - SupercomputingAccelerating Communications in Federated Applications with Transparent Object ProxiesJ. Gregory Pauloski, Valerie Hayot-Sasson, Logan Ward, Nathaniel Hudson, Charlie Sabino, Matt Baughman, Kyle Chard, and Ian FosterIn Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, Oct 2023(Accepted for publication)
@inproceedings{pauloski2023accelerating, title = {Accelerating Communications in Federated Applications with Transparent Object Proxies}, author = {Pauloski, J. Gregory and Hayot-Sasson, Valerie and Ward, Logan and Hudson, Nathaniel and Sabino, Charlie and Baughman, Matt and Chard, Kyle and Foster, Ian}, booktitle = {Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis}, year = {2023}, publisher = {Association for Computing Machinery}, eprint = {2305.09593}, archiveprefix = {arXiv}, primaryclass = {cs.DC}, note = {(Accepted for publication)}, } - TECSDeadline-Aware Task Offloading for Vehicular Edge Computing Networks Using Traffic Lights DataPratham Oza, Nathaniel Hudson, Thidapat Chantem, and Hana KhamfroushACM Transactions on Embededded Computing Systems, Apr 2023Just Accepted
As vehicles become increasingly automated, novel vehicular applications emerge to enhance the safety and security of the vehicles and improve user experience. This brings ever-increasing data and resource requirements for timely computation on the vehicle’s on-board computing systems. To alleviate these demands, prior work propose deploying vehicular edge computing (VEC) resources on the road-side units (RSUs) in the traffic infrastructure to which the vehicles can communicate and offload compute intensive tasks. Due to limited communication range of these RSUs, the communication link between the vehicles and the RSUs and therefore the response times of the offloaded applications are significantly impacted by vehicle’s mobility through road traffic. Existing task offloading strategies do not consider the influence of traffic lights on vehicular mobility while offloading workloads on the RSUs, and thereby cause deadline misses and quality-of-service (QoS) reduction for the offloaded tasks. In this paper, we present a novel task model that captures time and location-specific requirements for vehicular applications. We then present a deadline-based strategy that incorporates traffic light data to opportunistically offload tasks. Our approach allows up to (33%) more tasks to be offloaded onto the RSUs, compared to existing work, without causing any deadline misses and thereby maximizing the resource utilization on the RSUs.
@article{oza2023deadline, author = {Oza, Pratham and Hudson, Nathaniel and Chantem, Thidapat and Khamfroush, Hana}, title = {Deadline-Aware Task Offloading for Vehicular Edge Computing Networks Using Traffic Lights Data}, year = {2023}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, issn = {1539-9087}, url = {https://doi.org/10.1145/3594541}, doi = {10.1145/3594541}, note = {Just Accepted}, journal = {ACM Transactions on Embededded Computing Systems}, month = apr, keywords = {edge computing, task offloading, connected traffic infrastructure}, } - ICPESearching for the Ground Truth: Assessing the Similarity of Benchmarking RunsAndré Bauer, Martin Straesser, Mark Leznik, Marius Hadry, Lukas Beierlieb, Nathaniel Hudson, Kyle Chard, Samuel Kounev, and Ian FosterIn 2023 ACM/SPEC International Conference on Performance Engineering Data Challenge Track, Apr 2023
Stable and repeatable measurements are essential for comparing the performance of different systems or applications, and benchmarks are used to ensure accuracy and replication. However, if the corresponding measurements are not stable and repeatable, wrong conclusions can be drawn. To facilitate the task of determining whether the measurements are similar, we used a data set of 586 micro-benchmarks to (i) analyze the data set itself, (ii) examine an approach from related work, and (iii) propose and evaluate a heuristic. To evaluate the different approaches, we perform a peer review to assess the dissimilarity of the benchmark runs. Our results show that this task is challenging even for humans and that our heuristic exhibits a sensitivity of 92%.
@inproceedings{bauer2023searching, title = {Searching for the Ground Truth: Assessing the Similarity of Benchmarking Runs}, author = {Bauer, André and Straesser, Martin and Leznik, Mark and Hadry, Marius and Beierlieb, Lukas and Hudson, Nathaniel and Chard, Kyle and Kounev, Samuel and Foster, Ian}, booktitle = {2023 ACM/SPEC International Conference on Performance Engineering Data Challenge Track}, year = {2023}, publisher = {Association for Computing Machinery}, } - PerComBalancing federated learning trade-offs for heterogeneous environmentsMatt Baughman, Nathaniel Hudson, Ian Foster, and Kyle ChardIn 2023 IEEE International Conference on Pervasive Computing and Communications (PerCom) Work in Progress, Apr 2023
Federated Learning (FL) is an enabling technology for supporting distributed machine learning across several devices on decentralized data. A critical challenge when FL in practice is the system resource heterogeneity of worker devices that train the ML model locally. FL workflows can be run across diverse computing devices, from sensors to High Performance Computing (HPC) clusters; however, these resource disparities may result in some devices being too burdened by the task of training and thus struggle to perform robust training when compared to more high-power devices (or clusters). Techniques can be applied to reduce the cost of training on low-power devices, such as reducing the number of epochs to perform during training. However, such techniques may also negatively harm the performance of the locally-trained model, introducing a resource-model performance trade-off. In this work, we perform robust experimentation with the aim of balancing this resource-model performance trade-off in FL. Our results provide intuition for how training hyper-parameters can be tuned to improve this trade-off in FL.
@inproceedings{baughman2023balancing, title = {Balancing federated learning trade-offs for heterogeneous environments}, author = {Baughman, Matt and Hudson, Nathaniel and Foster, Ian and Chard, Kyle}, booktitle = {2023 IEEE International Conference on Pervasive Computing and Communications (PerCom) Work in Progress}, year = {2023}, publisher = {Institute of Electrical and Electronics Engineers}, }
2022
- Cloud ContinuumHierarchical and Decentralised Federated LearningOmer Rana, Theodoros Spyridopoulos, Nathaniel Hudson, Matt Baughman, Kyle Chard, Ian Foster, and Aftab KhanIn 2022 Cloud Computing, Apr 2022
Federated learning has shown enormous promise as a way of training ML models in distributed environments while reducing communication costs and protecting data privacy. However, the rise of complex cyber-physical systems, such as the Internet-of-Things, presents new challenges that are not met with traditional FL methods. Hierarchical Federated Learning extends the traditional FL process to enable more efficient model aggregation based on application needs or characteristics of the deployment environment (e.g., resource capabilities and/or network connectivity). It illustrates the benefits of balancing processing across the cloud-edge continuum. Hierarchical Federated Learning is likely to be a key enabler for a wide range of applications, such as smart farming and smart energy management, as it can improve performance and reduce costs, whilst also enabling FL workflows to be deployed in environments that are not well-suited to traditional FL. Model aggregation algorithms, software frameworks, and infrastructures will need to be designed and implemented to make such solutions accessible to researchers and engineers across a growing set of domains. H-FL also introduces a number of new challenges. For instance, there are implicit infrastructural challenges. There is also a trade-off between having generalised models and personalised models. If there exist geographical patterns for data (e.g., soil conditions in a smart farm likely are related to the geography of the region itself), then it is crucial that models used locally can consider their own locality in addition to a globally-learned model. H-FL will be crucial to future FL solutions as it can aggregate and distribute models at multiple levels to optimally serve the trade-off between locality dependence and global anomaly robustness.
@inproceedings{rana2023hierarchical, title = {Hierarchical and Decentralised Federated Learning}, author = {Rana, Omer and Spyridopoulos, Theodoros and Hudson, Nathaniel and Baughman, Matt and Chard, Kyle and Foster, Ian and Khan, Aftab}, booktitle = {2022 Cloud Computing}, pages = {1--9}, year = {2022}, } - eScienceFLoX: Federated learning with FaaS at the edgeNikita Kotsehub, Matt Baughman, Ryan Chard, Nathaniel Hudson, Panos Patros, Omer Rana, Ian Foster, and Kyle ChardIn 2022 IEEE International Conference on e-Science, Dec 2022
Federated learning (FL) is a technique for distributed machine learning that enables the use of siloed and distributed data. With FL, individual machine learning models are trained separately and then only model parameters (e.g., weights in a neural network) are shared and aggregated to create a global model, allowing data to remain in its original environment. While many applications can benefit from FL, existing frameworks are incomplete, cumbersome, and environment-dependent. To address these issues, we present FLoX, an FL framework built on the funcX federated serverless computing platform. FLoX decouples FL model training/inference from infrastructure management and thus enables users to easily deploy FL models on one or more remote computers with a single line of Python code. We evaluate FLoX using three benchmark datasets deployed on ten heterogeneous and distributed compute endpoints. We show that FLoX incurs minimal overhead, especially with respect to the large communication overheads between endpoints for data transfer. We show how balancing the number of samples and epochs with respect to the capacities of participating endpoints can significantly reduce training time with minimal reduction in accuracy. Finally, we show that global models consistently outperform any single model on average by 8%.
@inproceedings{kotsehub2022flox, title = {{FLoX}: Federated learning with {FaaS} at the edge}, author = {Kotsehub, Nikita and Baughman, Matt and Chard, Ryan and Hudson, Nathaniel and Patros, Panos and Rana, Omer and Foster, Ian and Chard, Kyle}, booktitle = {2022 IEEE International Conference on e-Science}, pages = {11-20}, day = {14}, month = dec, year = {2022}, doi = {10.1109/eScience55777.2022.00016}, publisher = {Institute of Electrical and Electronics Engineers}, } - SMARTCOMP
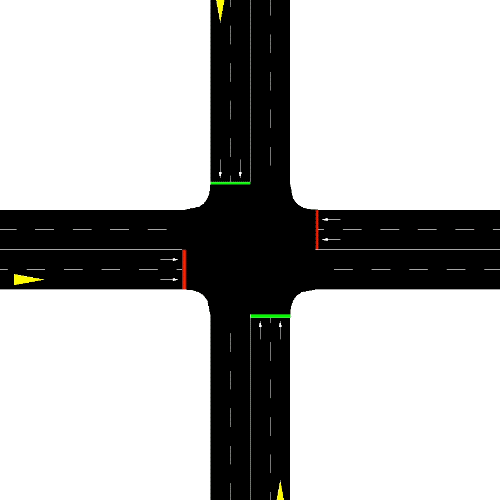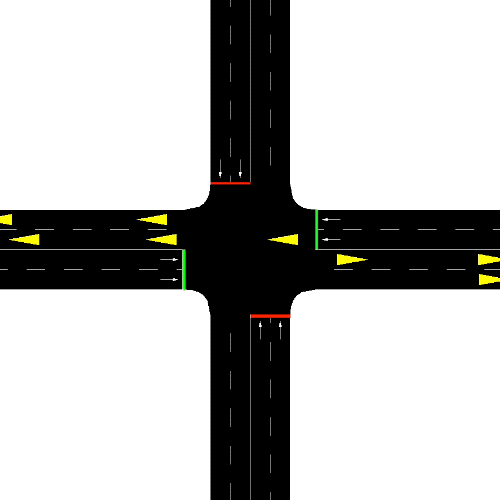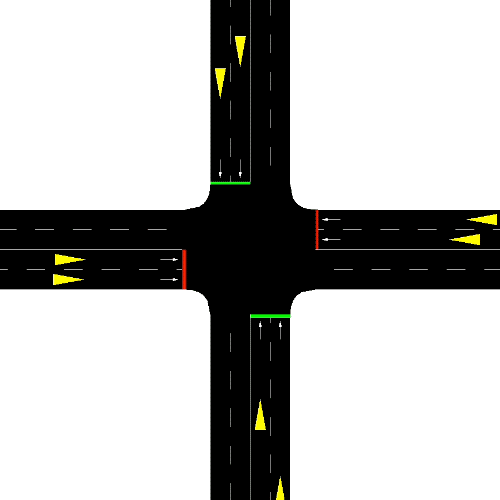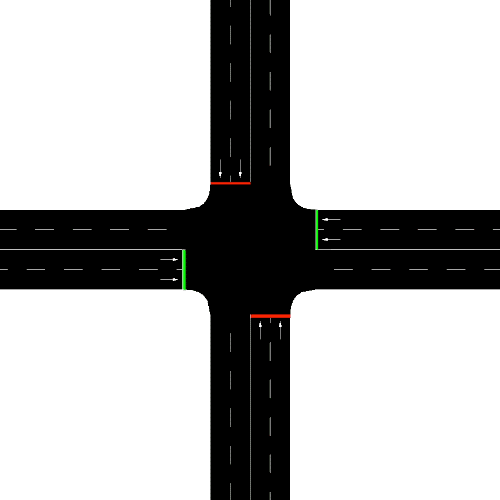 Smart Edge-Enabled Traffic Light Control: Improving Reward-Communication Trade-offs with Federated Reinforcement LearningNathaniel Hudson, Pratham Oza, Hana Khamfroush, and Chantem ThidapatIn 2022 IEEE International Conference on Smart Computing (SMARTCOMP), Jul 2022
Smart Edge-Enabled Traffic Light Control: Improving Reward-Communication Trade-offs with Federated Reinforcement LearningNathaniel Hudson, Pratham Oza, Hana Khamfroush, and Chantem ThidapatIn 2022 IEEE International Conference on Smart Computing (SMARTCOMP), Jul 2022Traffic congestion is a costly phenomenon of every-day life. Reinforcement Learning (RL) is a promising solution due to its applicability to solving complex decision-making problems in highly dynamic environments. To train smart traffic lights using RL, large amounts of data is required. Recent RL-based approaches consider training to occur on some nearby server or a remote cloud server. However, this requires that traffic lights all communicate their raw data to some central location. For large road systems, communication cost can be impractical, particularly if traffic lights collect heavy data (e.g., video, LIDAR). As such, this work pushes training to the traffic lights directly to reduce communication cost. However, completely independent learning can reduce the performance of trained models. As such, this work considers the recent advent of Federated Reinforcement Learning (FedRL) for edge-enabled traffic lights so they can learn from each other’s experience by periodically aggregating locally-learned policy network parameters rather than share raw data, hence keeping communication costs low. To do this, we propose the SEAL framework which uses an intersection-agnostic representation to support FedRL across traffic lights controlling heterogeneous intersection types. We then evaluate our FedRL approach against Centralized and Decentralized RL strategies. We compare the reward-communication trade-offs of these strategies. Our results show that FedRL is able to reduce the communication costs associated with Centralized training by 36.24%; while only seeing a 2.11% decrease in average reward (i.e., decreased traffic congestion).
@inproceedings{hudson2022smart, title = {Smart Edge-Enabled Traffic Light Control: Improving Reward-Communication Trade-offs with Federated Reinforcement Learning}, author = {Hudson, Nathaniel and Oza, Pratham and Khamfroush, Hana and Thidapat, Chantem}, booktitle = {2022 IEEE International Conference on Smart Computing (SMARTCOMP)}, volume = {18}, number = {6}, pages = {403--404}, month = jul, year = {2022}, publisher = {Institute of Electrical and Electronics Engineers}, } - CCNCCommunication-Loss Trade-Off in Federated Learning: A Distributed Client Selection AlgorithmMinoo Hosseinzadeh, Nathaniel Hudson, Sam Heshmati, and Hana KhamfroushIn 2022 IEEE 19th Annual Consumer Communications & Networking Conference (CCNC), May 2022
Mass data generation occurring in the Internet-of-Things (IoT) requires processing to extract meaningful information. Deep learning is commonly used to perform such processing. However, due to the sensitive nature of these data, it is important to consider data privacy. As such, federated learning (FL) has been proposed to address this issue. FL pushes training to the client devices and tasks a central server with aggregating collected model weights to update a global model. However, the transmission of these model weights can be costly, gradually. The trade-off between communicating model weights for aggregation and the loss provided by the global model remains an open problem. In this work, we cast this trade-off problem of client selection in FL as an optimization problem. We then design a Distributed Client Selection (DCS) algorithm that allows client devices to decide to participate in aggregation in hopes of minimizing overall communication cost — while maintaining low loss. We evaluate the performance of our proposed client selection algorithm against standard FL and a state-of-the-art client selection algorithm, called Power-of-Choice (PoC), using CIFAR-10, FMNIST, and MNIST datasets. Our experimental results confirm that our DCS algorithm is able to closely match the loss provided by the standard FL and PoC, while on average reducing the overall communication cost by nearly 32.67% and 44.71% in comparison to standard FL and PoC, respectively.
@inproceedings{hosseinzadeh2022communication, author = {Hosseinzadeh, Minoo and Hudson, Nathaniel and Heshmati, Sam and Khamfroush, Hana}, booktitle = {2022 IEEE 19th Annual Consumer Communications & Networking Conference (CCNC)}, title = {Communication-Loss Trade-Off in Federated Learning: A Distributed Client Selection Algorithm}, year = {2022}, pages = {1-6}, doi = {10.1109/CCNC49033.2022.9700601}, }
2021
- ICCCNQoS-Aware Placement of Deep Learning Services on the Edge with Multiple Service ImplementationsNathaniel Hudson, Hana Khamfroush, and Daniel E. LucaniIn 2021 IEEE International Conference on Computer Communications and Networks (ICCCN) Big Data and Machine Learning for Networking (BDMLN) Workshop, May 2021
Mobile edge computing pushes computationally-intensive services closer to the user to provide reduced delay due to physical proximity. This has led many to consider deploying deep learning models on the edge – commonly known as edge intelligence (EI). EI services can have many model implementations that provide different QoS. For instance, one model can perform inference faster than another (thus reducing latency) while achieving less accuracy when evaluated. In this paper, we study joint service placement and model scheduling of EI services with the goal to maximize Quality-of-Servcice (QoS) for end users where EI services have multiple implementations to serve user requests, each with varying costs and QoS benefits. We cast the problem as an integer linear program and prove that it is NP-hard. We then prove the objective is equivalent to maximizing a monotone increasing, submodular set function and thus can be solved greedily while maintaining a (1 – 1/e)-approximation guarantee. We then propose two greedy algorithms: one that theoretically guarantees this approximation and another that empirically matches its performance with greater efficiency. Finally, we thoroughly evaluate the proposed algorithm for making placement and scheduling decisions in both synthetic and real-world scenarios against the optimal solution and some baselines. In the real-world case, we consider real machine learning models using the ImageNet 2012 data-set for requests. Our numerical experiments empirically show that our more efficient greedy algorithm is able to approximate the optimal solution with a 0.904 approximation on average, while the next closest baseline achieves a 0.607 approximation on average.
@inproceedings{hudson2021qos, title = {QoS-Aware Placement of Deep Learning Services on the Edge with Multiple Service Implementations}, author = {Hudson, Nathaniel and Khamfroush, Hana and Lucani, Daniel E.}, booktitle = {2021 IEEE International Conference on Computer Communications and Networks (ICCCN) Big Data and Machine Learning for Networking (BDMLN) Workshop}, volume = {18}, number = {6}, pages = {403--404}, year = {2021}, publisher = {Institute of Electrical and Electronics Engineers}, } - ICCCNA Framework for Edge Intelligent Smart Distribution Grids via Federated LearningNathaniel Hudson, Md Jakir Hossain, Minoo Hosseinzadeh, Hana Khamfroush, Mahshid Rahnamay-Naeini, and Nasir GhaniIn 2021 IEEE International Conference on Computer Communications and Networks (ICCCN), May 2021
Recent advances in distributed data processing and machine learning provide new opportunities to enable critical, time-sensitive functionalities of smart distribution grids in a secure and reliable fashion. Combining the recent advents of edge computing (EC) and edge intelligence (EI) with existing advanced metering infrastructure (AMI) has the potential to reduce overall communication cost, preserve user privacy, and provide improved situational awareness. In this paper, we provide an overview for how EC and EI can supplement applications relevant to AMI systems. Additionally, using such systems in tandem can enable distributed deep learning frameworks (e.g., federated learning) to empower distributed data processing and intelligent decision making for AMI. Finally, to demonstrate the efficacy of this considered architecture, we approach the non-intrusive load monitoring (NILM) problem using federated learning to train a deep recurrent neural network architecture in a 2-tier and 3-tier manner. In this approach, smart homes locally train a neural network using their metering data and only share the learned model parameters with AMI components for aggregation. Our results show this can reduce communication cost associated with distributed learning, as well as provide an immediate layer of privacy, due to no raw data being communicated to AMI components. Further, we show that FL is able to closely match the model loss provided by standard centralized deep learning where raw data is communicated for centralized training.
@inproceedings{hudson2021framework, title = {A Framework for Edge Intelligent Smart Distribution Grids via Federated Learning}, author = {Hudson, Nathaniel and Hossain, Md Jakir and Hosseinzadeh, Minoo and Khamfroush, Hana and Rahnamay-Naeini, Mahshid and Ghani, Nasir}, booktitle = {2021 IEEE International Conference on Computer Communications and Networks (ICCCN)}, pages = {1-9}, year = {2021}, publisher = {Institute of Electrical and Electronics Engineers}, } - DySPANJoint Compression and Offloading Decisions for Deep Learning Services in 3-Tier Edge SystemsMinoo Hosseinzadeh, Nathaniel Hudson, Xiaobo Zhao, Hana Khamfroush, and Daniel E. LucaniIn 2021 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Jan 2021
Task offloading in edge computing infrastructure remains a challenge for dynamic and complex environments, such as Industrial Internet-of-Things. The hardware resource constraints of edge servers must be explicitly considered to ensure that system resources are not overloaded. Many works have studied task offloading while focusing primarily on ensuring system resilience. However, in the face of deep learning-based services, model performance with respect to loss/accuracy must also be considered. Deep learning services with different implementations may provide varying amounts of loss/accuracy while also being more complex to run inference on. That said, communication latency can be reduced to improve overall Quality-of-Service by employing compression techniques. However, such techniques can also have the side-effect of reducing the loss/accuracy provided by deep learning-based service. As such, this work studies a joint optimization problem for task offloading decisions in 3-tier edge computing platforms where decisions regarding task offloading are made in tandem with compression decisions. The objective is to optimally offload requests with compression such that the trade-off between latency-accuracy is not greatly jeopardized. We cast this problem as a mixed integer nonlinear program. Due to its nonlinear nature, we then decompose it into separate subproblems for offloading and compression. An efficient algorithm is proposed to solve the problem. Empirically, we show that our algorithm attains roughly a 0.958-approximation of the optimal solution provided by a block coordinate descent method for solving the two sub-problems back-to-back.
@inproceedings{hosseinzadeh2021joint, title = {Joint Compression and Offloading Decisions for Deep Learning Services in 3-Tier Edge Systems}, author = {Hosseinzadeh, Minoo and Hudson, Nathaniel and Zhao, Xiaobo and Khamfroush, Hana and Lucani, Daniel E.}, booktitle = {2021 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN)}, pages = {254-261}, month = jan, year = {2021}, publisher = {Institute of Electrical and Electronics Engineers} }
2020
- TNSEBehavioral Information Diffusion for Opinion Maximization in Online Social NetworksNathaniel Hudson, and Hana KhamfroushIEEE Transactions on Network Science and Engineering (TNSE), Oct 2020Recipient of the 2021 Outstanding Student Paper award from the University of Kentucky Department of Computer Science.
Online social networks provide a platform to diffuse information and influence people’s opinion. Conventional models for information diffusion do not take into account the specifics of each users’ personality, behavior, and their opinion. This work adopts the “Big Five” model from the social sciences to ascribe each user node with a personality. We propose a behavioral independent cascade (BIC) model that considers the personalities and opinions of user nodes when computing propagation probabilities for diffusion. We use this model to study the opinion maximization (OM) problem and prove it is NP-hard under our BIC model. Under the BIC model, we show that the objective function of the proposed OM problem is not submodular. We then propose an algorithm to solve the OM problem in linear-time based on a state-of-the-art influence maximization (IM) algorithm. We run extensive simulations under four cases where initial opinion is distributed in polarized/non-polarized and community/non-community cases. We find that when communities are polarized, activating a large number of nodes is ineffective towards maximizing opinion. Further, we find that our proposed algorithm outperforms state-of-the-art IM algorithms in terms of maximizing opinion in uniform opinion distribution-despite activating fewer nodes to be spreaders.
@article{hudson2020behavioral, author = {Hudson, Nathaniel and Khamfroush, Hana}, journal = {IEEE Transactions on Network Science and Engineering (TNSE)}, title = {Behavioral Information Diffusion for Opinion Maximization in Online Social Networks}, volume = {8}, number = {2}, publisher = {Institute of Electrical and Electronics Engineers}, month = oct, year = {2020}, doi = {10.1109/TNSE.2020.3034094}, pages = {1259-1268}, note = {Recipient of the 2021 Outstanding Student Paper award from the University of Kentucky Department of Computer Science.}, } - GCImproving the Accuracy-Latency Trade-off of Edge-Cloud Computation Offloading for Deep Learning ServicesXiaobo Zhao, Minoo Hosseinzadeh, Nathaniel Hudson, Hana Khamfroush, and Daniel E. LucaniIn 2020 IEEE Globecom Workshops, Dec 2020
Offloading tasks to the edge or the Cloud has the potential to improve accuracy of classification and detection tasks as more powerful hardware and machine learning models can be used. The downside is the added delay introduced for sending the data to the Edge/Cloud. In delay-sensitive applications, it is usually necessary to strike a balance between accuracy and latency. However, the state of the art typically considers offloading all-or-nothing decisions, e.g., process locally or send all available data to the Edge (Cloud). Our goal is to expand the options in the accuracy-latency trade-off by allowing the source to send a fraction of the total data for processing. We evaluate the performance of image classifiers when faced with images that have been purposely reduced in quality in order to reduce traffic costs. Using three common models (SqueezeNet, GoogleNet, ResNet) and two data sets (Caltech101, ImageNet) we show that the Gompertz function provides a good approximation to determine the accuracy of a model given the fraction of the data of the image that is actually conveyed to the model. We formulate the offloading decision process using this new flexibility and show that a better overall accuracy-latency tradeoff is attained: 58% traffic reduction, 25% latency reduction, as well as 12% accuracy improvement.
@inproceedings{zhao2020improving, title = {Improving the Accuracy-Latency Trade-off of Edge-Cloud Computation Offloading for Deep Learning Services}, author = {Zhao, Xiaobo and Hosseinzadeh, Minoo and Hudson, Nathaniel and Khamfroush, Hana and Lucani, Daniel E.}, booktitle = {2020 IEEE Globecom Workshops}, doi = {10.1109/GCWkshps50303.2020.9367470}, pages = {1-6}, month = dec, year = {2020} } - ICNCA Proximity-Based Generative Model for Online Social Network TopologiesEmory Hufbauer, Nathaniel Hudson, and Hana KhamfroushIn 2020 International Conference on Computing, Networking and Communications (ICNC), Feb 2020
Online social networks (OSN) are an increasingly powerful force for information diffusion and opinion sharing in society. Thus, understanding and modeling their structure and behavior is critical. Researchers need vast databases of self-contained, appropriately-sized OSN topologies in order to test and train new algorithms and models to solve problems related to these platforms. In this paper, we present a flexible, robust, and novel model for generating synthetic networks which closely resemble real OSN network systems (e.g., Facebook and Twitter) that include community structures. We also present an automated parameter tuner which can match the model’s output to a given OSN topology. The model can then be used as a data factory to generate testbeds of synthetic topologies which closely resemble the given sample. We compare our model, tuned to match two large real-world OSN network samples, with the Barabási-Albert model and the Lancichinetti-Fortunato-Radicchi benchmark used as baselines. We find that output of our proposed generative model more closely matches the target topologies, than either model, on a variety of important metrics — including clustering coefficient, modularity, assortativity, and average path length. Our model also organically generates robust, realistic communities, with non-trivial inter- and intra-community structure.
@inproceedings{hufbauer2020proximity, author = {Hufbauer, Emory and Hudson, Nathaniel and Khamfroush, Hana}, booktitle = {2020 International Conference on Computing, Networking and Communications (ICNC)}, title = {A Proximity-Based Generative Model for Online Social Network Topologies}, year = {2020}, pages = {648-653}, keywords = {}, doi = {10.1109/ICNC47757.2020.9049662}, issn = {2325-2626}, month = feb, } - SMARTCOMPSmart Advertisement for Maximal Clicks in Online Social Networks Without User DataNathaniel Hudson, Hana Khamfroush, Brent Harrison, and Adam CraigIn 2020 IEEE International Conference on Smart Computing (SMARTCOMP), Sep 2020
Smart cities are a growing paradigm in the design of systems that interact with one another for informed and efficient decision making, empowered by data and technology, of resources in a city. The diffusion of information to citizens in a smart city will rely on social trends and smart advertisement. Online social networks (OSNs) are prominent and increasingly important platforms to spread information, observe social trends, and advertise new products. To maximize the benefits of such platforms in sharing information, many groups invest in finding ways to maximize the expected number of clicks as a proxy of these platform’s performance. As such, the study of click-through rate (CTR) prediction of advertisements, in environments like online social media, is of much interest. Prior works build machine learning (ML) using user-specific data to classify whether a user will click on an advertisement or not. For our work, we consider a large set of Facebook advertisement data (with no user data) and categorize targeted interests into thematic groups we call conceptual nodes. ML models are trained using the advertisement data to perform CTR prediction with conceptual node combinations. We then cast the problem of finding the optimal combination of conceptual nodes as an optimization problem. Given a certain budget k, we are interested in finding the optimal combination of conceptual nodes that maximize the CTR. We discuss the hardness and possible NP-hardness of the optimization problem. Then, we propose a greedy algorithm and a genetic algorithm to find near-optimal combinations of conceptual nodes in polynomial time, with the genetic algorithm nearly matching the optimal solution. We observe that simple ML models can exhibit the high Pearson correlation coefficients w.r.t. click predictions and real click values. Additionally, we find that the conceptual nodes of “politics”, “celebrity”, and “organization” are notably more influential than other considered conceptual nodes.
@inproceedings{hudson2020smart, author = {Hudson, Nathaniel and Khamfroush, Hana and Harrison, Brent and Craig, Adam}, booktitle = {2020 IEEE International Conference on Smart Computing (SMARTCOMP)}, title = {Smart Advertisement for Maximal Clicks in Online Social Networks Without User Data}, year = {2020}, pages = {172-179}, doi = {10.1109/SMARTCOMP50058.2020.00042}, month = sep, }
2019
- ASNInfluence spread in two-layer interdependent networks: designed single-layer or random two-layer initial spreaders?Hana Khamfroush, Nathaniel Hudson, Samuel Iloo, and Mahshid Rahnamay-NaeiniSpringer Applied Network Science, Dec 2019
Influence spread in multi-layer interdependent networks (M-IDN) has been studied in the last few years; however, prior works mostly focused on the spread that is initiated in a single layer of an M-IDN. In real world scenarios, influence spread can happen concurrently among many or all components making up the topology of an M-IDN. This paper investigates the effectiveness of different influence spread strategies in M-IDNs by providing a comprehensive analysis of the time evolution of influence propagation given different initial spreader strategies. For this study we consider a two-layer interdependent network and a general probabilistic threshold influence spread model to evaluate the evolution of influence spread over time. For a given coupling scenario, we tested multiple interdependent topologies, composed of layers A and B, against four cases of initial spreader selection: (1) random initial spreaders in A, (2) random initial spreaders in both A and B, (3) targeted initial spreaders using degree centrality in A, and (4) targeted initial spreaders using degree centrality in both A and B. Our results indicate that the effectiveness of influence spread highly depends on network topologies, the way they are coupled, and our knowledge of the network structure — thus an initial spread starting in only A can be as effective as initial spread starting in both A and B concurrently. Similarly, random initial spread in multiple layers of an interdependent system can be more severe than a comparable initial spread in a single layer. Our results can be easily extended to different types of event propagation in multi-layer interdependent networks such as information/misinformation propagation in online social networks, disease propagation in offline social networks, and failure/attack propagation in cyber-physical systems.
@article{khamfroush2019influence, author = {Khamfroush, Hana and Hudson, Nathaniel and Iloo, Samuel and Rahnamay-Naeini, Mahshid}, journal = {Springer Applied Network Science}, number = {1}, title = {Influence spread in two-layer interdependent networks: designed single-layer or random two-layer initial spreaders?}, volume = {4}, month = dec, year = {2019}, } - ICNCOn the Effectiveness of Standard Centrality Metrics for Interdependent NetworksNathaniel Hudson, Matthew Turner, Asare Nkansah, and Hana KhamfroushIn 2020 IEEE International Conference on Computing, Networking, and Communications (ICNC), Feb 2019
This paper investigates the effectiveness of standard centrality metrics for interdependent networks (IDN) in identifying important nodes in preventing catastrophic failure propagation. To show the need for designing specialized centrality metrics for IDNs, we compare the performance of these metrics in an IDN under two different scenarios: i) the nodes with highest centrality of networks composing an IDN are selected separately and ii) the nodes with highest centrality of the entire IDN represented as one single network are calculated. To investigate the resiliency of an IDN, a threshold-based failure propagation model is used to simulate the evolution of failure propagation over time. The nodes with highest centrality are chosen and are assumed to be resistant w.r.t failure. Extensive simulation is conducted to compare the usefulness of standard metrics to stop or slow down the failure propagation in an IDN. Finally a new metric of centrality tailored for interdependent networks is proposed and evaluated. Also, useful guidelines on designing new metrics are presented.
@inproceedings{hudson2019centrality, title = {On the Effectiveness of Standard Centrality Metrics for Interdependent Networks}, author = {Hudson, Nathaniel and Turner, Matthew and Nkansah, Asare and Khamfroush, Hana}, booktitle = {2020 IEEE International Conference on Computing, Networking, and Communications (ICNC)}, doi = {10.1109/ICCNC.2019.8685586}, issn = {2325-2626}, pages = {1-6}, month = feb, year = {2019}, }